
科幻小說鍊成計畫
前言
十一月越來越逼進了,那是一年一度的國家小說寫作月(National Novel Writing Month)了,身為文藝愛好者的我,怎麼可能錯過這場盛事呢? 雖然還有好一段時間,但是現在不好好開始規劃、慢慢利用零碎的時間持之以恆的學習,應該很難產生出有趣的成果。 在年初時候,我對遊戲相關的演算法非常感興趣,當時實作了尋找路徑的A*演算法、以及取得視野的ray-casting,接著慢慢地把興趣轉向了程序化生成(procedural generation)。 在網路上找到了一篇滿有趣的文章,作者是由奇幻小說的地名為發想,想要創造一組虛構的語言來對小說中的世界進行命名,文章中一步步從語言學的角度,由音節、字符逐步構建簡單的語言。 仔細看了一下文章開頭,天那!竟然是為了NaNoGenMo,國家小說產生月! 在寒冬時節,想像屋外冰天雪地,愜意地坐在火爐邊寫小說、讀小說,外加一杯香濃的熱可可,真是人生一大享受。 但是這時一群腦洞大開的程式員,不畏寒冬守在螢幕前敲著鍵盤,打算用程式碼來拯救全世界。
「你用筆來寫小說?」
「太遜了,我們都用程式來生成小說」
引起我極大興趣的另一個原因是,去年年底在reddit上讀到了關於Machine Learning conference的報導,其中Generative Adversarial Networks(GAN)受到高度的評價,被譽為是近十年來最棒的演算法。 最近台大李宏毅教授也來到中心演講也是在介紹GAN,其中就有唐詩鍊成的範例,雖然語句不太有意義,但我認為是一個很好的參考指標。 接著是清大張俊盛教授來中心介紹自然語言處理,這個課程講得概念很粗略,反而是老師為自然語言、機器翻譯畫了一個美好大餅,希望吸引博士生加入一起努力(讀博士?算了吧!)。 不過重點有提到,目前主流使用的Neural Machine Translation,由於忽略的語句的文法構成,仍有許多值得改進的地方。 聽完這一系列的演講,內心的熱血已在蠢蠢欲動,所以想利用NaNoGenMo這個性質比較輕鬆的活動,慢慢從頭規劃程式並產生至少能讀的科幻小說。
專案規劃
在施放鍊金術前,總是要有基本素材才能進行鍊成,直接無中生有已經不是鍊金術了,那已經是另一個次元位面的事情了。 大致上先將目前計畫規劃為下列四大部分,再逐一慢慢完成每個區塊。
專案區塊:
- 網路爬蟲:收集已在公共領域、不會侵權的小說文章。
- 文檔正規化:文檔資料前處理。
- 構建文句產生器:參考這篇文章,利用LSTM自動產生文句。
- 利用GAN鍊出最佳文章
先建立一個Github Project: 小說煉金術師來存放我的工作進度。
網路爬蟲
網站資源
為了要生成科幻小說,想當然耳要先去找尋相關類型的文章,有礙於著作權法,所以只能找尋已經開放於公共領域(public domain)的小說。 在網路上搜索相關資訊的過程中,發現了一篇介紹25個存放公共領域書籍的免費網站,裡面有很完整的介紹。 其中最大的網站,Project Gutenberg,是我心目中收集鍊金素材的最佳網站,但是很不幸它的使用條款其中一條寫道:
The Project Gutenberg website is for human users only. Any real or perceived use of automated tools to access our site will result in a block of your IP address. This site utilizes cookies, captchas and related technologies to help assure the site is maximally available for human users only.
雖然之前看的書本裡,介紹到Web Scraping也是從Project Gutenberg下載羅密歐與茱麗葉,但是身為腦包研究者一定先把25個網站一個個看過,再決定我們的行動方針。 在排名第6的Feedbooks也是有非常多的公共領域書籍,其中科幻類的就有1176本!但是看到使用條例,心也涼了一半,不過條款的力道似乎沒有像Project Gutenberg那麼嚴厲。
6.15 use any robot, spider, scraper, or other automated means to access the FeedBooks Website bypass any measures FeedBooks may use to prevent or restrict access to the FeedBooks Website
小王子曾說過:『沙漠之所以這麼美,是因為在某個角落裡,藏著一口井。星星好美,是因為一朵我們看不見的花。』 現在終於讓我找到了,那個藏在沙漠角落的那一口井了,那就是Manybooks,這個網站雖然也收集了Project Gutenberg及其他網路資源,但是使用條款中完全沒有限制網路爬蟲,簡直是佛心公司。
爬蟲程式撰寫
整體的主程式架構說明如下,概念是先取得網站上所有的小說類別,接著再搜尋相關語言選項。
由於個人就是偏好科幻小說,而這個計畫也叫做”科幻”小說鍊成計畫,當然挑選Science Fiction。
在語言選擇方面,由於網路上大部分的資料是英語,為了方便資料處理與模型建置,首選English。
接著一頁一頁的爬過所有科幻類的頁面,每一頁開始尋找所有書籍的連結,並將所有書籍的.epub檔案下載(因為有些書籍只有.epub檔案)。
最後搜尋下個頁面的按鈕,若無按鈕則結束程式。
程式架構:
- 連接書籍網站(http://manybooks.net/)
- 取得所有類別(Genre),並加以選取(預設Sci-Fi)
- 取得所有語言(Language),並加以選取(預設English)
- 連結頁面設定為:相關類別、語言總集的第一頁
- 連結頁面
- 抓取頁面內所有書籍(若頁面內沒有書籍則結束)
- 取得下一個頁面連結(若無下一頁按鈕則結束)
- To
step. 1
主程式
if __name__ == '__main__':
# Settings
file_dir = os.path.join(os.path.dirname(__file__),'epub')
url = 'manybooks.net'
# Create the folder to save scraped files
if not os.path.exists(file_dir):
os.makedirs(file_dir)
# select=54 : Science Fiction
genre_link = sel_genre(url, select=54)
# select=10 : English
lang = sel_language(genre_link, select=10)
# First page of the selected genre
page_link = genre_link + '/' + lang
while True:
# Access genre pages
print('access... %s' %page_link)
res = requests.get(page_link)
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem accessing genre page: %s' %(exc))
soup = bs4.BeautifulSoup(res.text)
try:
# Find books and download .epub files
download_books_in_page(url, soup, file_dir)
# Get "next page" button
button_elems = soup.select('a[title="next"]')[0]
page_link = 'http://%s%s' %(url, button_elems.get('href'))
except Exception as e:
# No "next page" button
print(e)
print('end of pages')
break首先我們要先取得所有小說的類型,如此一來方便我們未來的使用,可以挑選其他非科幻題材來鍊成文章。
def sel_genre(url='manybooks.net', select=None):
""" Select Genre
This function allows user to select a particular genre from "manybooks.net"
and it returns the link to the first page of selected genre.
Parameters
----------
url: string, default='manybooks.net'
The URL of "Manybooks".
select: int, default=None
The number of selection. If the value is None, the console will display
all the genres and requires an user input.
Return
------
link: string
The URL of the first page of the selected genre.
"""
genre_url = 'http://%s/%s' %(url, 'categories')
genre_dict = {}
genre_list = []
# Access genre catagories
print('access genres... %s' %genre_url)
res = requests.get(genre_url)
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem accessing genre catagories: %s' %(exc))
soup = bs4.BeautifulSoup(res.text)
# Get all genre elements
elems = soup.select('a[class="larger"]')
for elem in elems:
genre_name = elem.getText()
genre_link = 'http://%s%s' %(url, elem.get('href'))
genre_dict[genre_name] = genre_link
genre_list.append(genre_name)
# Display Genre Selection
if select == None:
for i in range(len(genre_list)):
print('[%d] : %s' %(i+1, genre_list[i]))
select = input('Select the Genre (no.) >> ')
if not (int(select) > 0 and int(select) < len(genre_list)+1):
raise ValueError('Wrong selection number!')
print('genre: %s' %genre_list[int(select)-1])
link = genre_dict[genre_list[int(select)-1]]
return link接著要選取對應的語言。
def sel_language(url, select=None):
""" Select Language
This function allows user to select a particular language in the pages of
each genre and it returns the link to the page of books with selected
language.
Parameters
----------
url: string
The URL of the first selected genre page.
select: int, default=None
The number of selection. If the value is None, the console will display
all the language and requires an user input.
Return
------
link: string
The URL of the first page of the selected genre and selected language.
"""
lang_dict = {}
lang_list = []
# Access language options
print('access language... %s' %url)
res = requests.get(url)
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem accessing language options: %s' %(exc))
soup = bs4.BeautifulSoup(res.text)
# Get all language option elements
elems = soup.select('option')
for elem in elems:
lang_name = elem.getText()
lang_value = elem.get('value')
lang_dict[lang_name] = lang_value
lang_list.append(lang_name)
# Display language Selection
if select == None:
for i in range(len(lang_list)):
print('[%d] : %s' %(i+1, lang_list[i]))
select = input('Select the Genre (no.) >> ')
if not (int(select) > 0 and int(select) < len(lang_list)+1):
raise ValueError('Wrong selection number!')
print('language: %s' %lang_list[int(select)-1])
return lang_dict[lang_list[int(select)- 1]]最後就是最重要,下載頁面的部份。首先是取得一整個頁面所有書籍的連結,每一頁約略有20本書。
def download_books_in_page(url, soup, file_dir):
"""Download Books in the Genre Pages
This function downloads all the books in a genre page and raise the stop
signal if there is no books in the page.
Parameters
----------
url: string
The root URL address.
soup: bs4.BeautifulSoup object
The object contains all the info. in the genre catagory page.
file_dir: sting
This is the folder to save the scraped files.
"""
try:
# has books
# Get book elements in the genre page
book_elems = soup.select('.grid_6.smallBook a')
book_links = [elem.get('href') for elem in book_elems]
book_names = [elem.getText() for elem in book_elems]
for i in range(len(book_links)):
# Download one book at a time
download_single_book(url, book_links[i], file_dir, book_names[i])
except:
# no book
raise ScraperError('Error: No books in this page!')類別頁面沒有書的時候,發出的以下自定義的Error。
class ScraperError(Exception):
""" Scraper Error
A custom error raised when there are troubles.
"""
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)最最最關鍵,下載書籍連結的部分如下。
def download_single_book(url, book_link, file_dir, book_name):
"""Download a single Book
This function download the particular book according to its book_link. We
use URL (see -> # Text file download link) instead of using selenium module
for better program control.
Parameters
----------
url: string
The root URL address.
book_link: string
The href of the book.
file_dir: string
This is the folder to save the scraped files.
book_name
This is the name(filename) of the book.
"""
# Text file download link
book_id = book_link[8:-5]
download_page = 'http://' + url + '/download-ebook?tid=' + book_id + \
'&book=1%3Aepub%3A.epub%3Aepub'
# Access the download page
print('-> access... %s' %(book_name))
res = requests.get(download_page)
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem accessing download page: %s' %(exc))
soup = bs4.BeautifulSoup(res.text)
# Get downloadable elements
download_elems = soup.select('a[rel="nofollow"]')
epub_link = [elem.get('href') for elem in download_elems if \
elem.get('href').endswith('.epub')][0]
# Download .epub file
download_link = 'http://%s%s' %(url, epub_link)
print('->-> access download link... %s' %(download_link))
res = requests.get(download_link, allow_redirects=True) # redirected!
try:
res.raise_for_status()
except Exception as exc:
print('There was a problem accessing download link: %s' %(exc))
print('->-> download... %s' %(book_name))
# Avoid file name errors
book_name = book_name.replace('/', '-')
book_name = book_name.replace('\\', '-')
book_name = book_name.replace(':', '-')
book_name = book_name.replace('*', '-')
book_name = book_name.replace('?', '-')
book_name = book_name.replace('\"', '-')
book_name = book_name.replace('>', '-')
book_name = book_name.replace('<', '-')
book_name = book_name.replace('|', '-')
# Custom file name
book_name = book_name.replace(' ', '-')
book_name = book_name.replace('\'', '')
book_name = book_name.replace(',', '')
# Write .epub file
cachesize = 1024
with open('%s/%s.epub' %(file_dir, book_name), 'wb') as write_file:
for chunk in res.iter_content(cachesize):
if len(chunk) % cachesize != 0:
chunk += b' ' * ( cachesize - len(chunk))
write_file.write(chunk)
# Employ random delay
time.sleep(3+random.randint(0,5))爬蟲程式小結
寫網路爬蟲還是滿有趣的一件事,可能是很少實際寫一個完整的爬蟲,所以能在新鮮感還沒退去前先把程式寫好。
而且小弟在每一個下載行為之後都會刻意隨機延遲3~8秒,自以為模擬人類瀏覽行為(哈:D)。
這隻爬蟲純粹使用requests跟BeautifulSoup這兩個套件,極力避免使用Selenium。
原因是在於最後者會控制到網頁瀏覽器,若非真的遇到無解的動態網頁才會使用,若只使用前兩者來對取得網站資料,只需在console介面下執行,相較之下速度快上不少。
這個爬蟲還是有缺點尚待改進,程式每次都是由第一頁開始抓取,若是遇到非預期程式中斷,則大俠請重新來過。
為了解決此問題,最後額外設計了一個變數last_item,當last_item=None時,一如往常地從第一頁開始爬起;但若last_item為任意書名,程式將直接略到那本書的頁面,並從那本書開始下載。
統計數據:
- 文件數量:1324
- 爬蟲時間:09:56:42
- 檔案大小:252 MB
網頁上顯示全部的英文科幻小說有1340筆,但是下載下來的.epub檔案僅有1324筆差距16筆,差距的資料應當寫一支程式來進行比對。
雖然差距的資料不多,但是本人身為一個低能好奇寶寶,還是得找出其中差異的原因。
最後測試結果得知,原來是有相同名稱的書本,所以爬蟲又要再做修改,爬蟲程式也有可能要重跑了…
詳見最終版本。
最終版統計數據:
- 文件數量:1340
- 爬蟲時間:09:21:38
- 檔案大小:265.7 MB
文檔正規化
爬蟲爬了好久竟然連一半的文章都還沒抓齊,與其看著reddit或PTT的文章顆顆笑,還不如接下來的準備工作。 文檔的正規化好比於資料的前置處理,依照之前研究的經驗,這部分應該會花費掉最多的功夫,預想大致的流程如下。
- 首先,將抓下來的
.epub文檔轉換成純文字的.txt文檔,可能會遭遇到檔案格式毀損、或是內文包含異常字符。 - 接著將處理過後的
.txt文檔拆解為兩個部分,一個是出版及檔案格式相關的metadata,另一個是純粹內文content。 - 最後處理
content部分應該最為複雜,content內可能包含非內容的目錄、章節標記、分隔符號,要規劃一個有系統的儲存格式方便後續模型建置。
檔案格式轉換
上網查詢了一下.epub轉.txt相關的程式,就這個ebooklib的程式最符合需求,而且大部分所需的package在Anaconda內都有了。
首先先fork到自己的Github,接著在專案中引入ebooklib,並且將ebooklib/epub.py中read_file副程式中的路徑comment起來(line 1298)。
這裡又學到了一招git submodule的專案管理方法(幹code、修code、用code),應用時機是在專案下用到其他專案,同時要維護兩個reposiroty的獨立版本。
從同仁那裏詢問到大致的使用方法,再加上完整的網路資料說明,輕鬆地加入了ebooklib。
Git submodules重點如下:
- 先fork原本的reposiroty方便進行修改
- 在要引入的傳案內使用
git submodule add YOUR_FORKED_REPO_URL - 利用
git submodule update --remote將submodule更新到最新的版本 - clone時使用
git clone --recursive YOUR_MAIN_PROJECT
雖然另一位同仁指出可以利用Bitbucket,將整個repository匯入到獨立的地方控管,但是這個做法跟Github上的fork根本一樣,為了方便個人管理還是使用fork。 如果也有人想要用Bitbucket來控管Github的專案,可以參考這一篇文章。
以下副程式利用了ebooklib,將單一檔案進行轉換。
def convert_epub_to_txt(epub_path, txt_path, encode='utf-8'):
""" Convert EPUB to TXT
This function converts the craped .epub files to .txt files.
Parameters
----------
epub_path: string
This is the path of a craped .epub file to be parsed.
txt_path: string
This is the path of the converted .txt file to be saved.
encode: string, default='utf-8'
The encoding method of the character set.
"""
try:
book = epub.read_epub(epub_path)
content = ''
# Get all html content in .epub
split = []
content = []
for doc in book.get_items_of_type(ebooklib.ITEM_DOCUMENT):
content.append(str('%s') %(doc.content))
split.append(doc.file_name)
# Sort the content by the split number
content = [x for (y, x) in sorted(zip(split, content))]
content = ''.join(content)
# Select the text part
soup = bs4.BeautifulSoup(content)
elems = soup.findAll(['h1', 'h2', 'h3', 'h4', 'p', 'pre'])
# elems = soup.findAll(class_=re.compile("^calibre")) # - Not general enough
lines = [(elem.getText() + '\n') for elem in elems]
except Exception as e:
# BadZipFile -> parse an empty .txt file
lines = []
print(e)
# Write .txt file
with open(txt_path, 'wb') as write_file:
write_file.writelines([line.encode(encode) for line in lines])不過解析.epub檔案,還是利用BeautifulSoup來處理網頁格式的檔案比較方便,由於只h1, h2, h3, h4, p, pre這些區塊的文字,也可能會有遺珠的可能性。
檔案大小分析
在進行更進一步的文檔正規劃之前,我們需要先對格式轉化後的資料進行分析,以便初步剃除毀損或不全的資料。
大概先以人眼分析得出.txt檔案大小大概分三類,第一類0 KB標準的毀天滅地.epub壓縮檔毀損;第二類約為1 KB有兩種可能,第一是檔案裡面就是沒文檔,如”1/2986”,第二是檔案結構異於常人、骨骼驚奇,如”After the Cure”;最後第三類就是大部分正常轉出的文檔。
def analyze_parsed_text(txt_dir, result_dir, threshold):
""" Analyze Parsed Text
This function will generate statistics of parsed .txt files.
Parameters
----------
txt_dir: string
This is the directory of the parsed .txt files.
result_dir: string
This is the directory to save the results of analyzed results.
threshold: float
This is file size (Kb) threshold. The files with size smaller than the
threshold will be considered as abnormal data.
Return
------
anomalies_name: list of strings
This list contains names of all the abnormal files.
"""
# Logging Settings
log_path = os.path.join(result_dir, 'parsed_file_stats.log')
log_name = 'analyze_parsed_text'
logger = set_logger(log_path, log_name, mode='w', format='%(message)s')
# Read parsed .txt files
txt_files = [x[2] for x in os.walk(txt_dir)][0]
file_size = []
for txt_file in txt_files:
file_size.append(os.path.getsize(os.path.join(txt_dir, txt_file)) \
/ 1000) # Unit in KB
# Sort the file by it's size
sorted_file = [x for (y, x) in sorted(zip(file_size, txt_files))]
sorted_size = sorted(file_size)
# Get abnormal files
anomalies_name = [sorted_file[i] for i in range(len(sorted_size)) \
if sorted_size[i] < threshold]
anomalies_size = [x for x in sorted_size if x < threshold]
# Print abnormal files
logger.info('Anomalies:')
for i in range(len(anomalies_name)):
logger.info('- %s (%.2f KB)' %(anomalies_name[i], anomalies_size[i]))
logger.info('Radio: %d / %d (%.4f %%)' %(len(anomalies_name), \
len(txt_files), len(anomalies_name) / len(txt_files) * 100))
# The minial-sized normal file for checking
logger.info('-- the minial-sized normal file: %s (%.2f KB) --' %( \
sorted_file[len(anomalies_name)], sorted_size[len(anomalies_name)]))
# Plot histogram
# Figure settings
fig_dir = os.path.join(result_dir, 'fig')
if not os.path.exists(fig_dir):
os.makedirs(fig_dir)
fig_size = (15, 5)
bin_interval = 10
dpi = 200
plt.figure(figsize=fig_size)
plt.title('Parsed .txt File Statistics')
plt.xlabel('File size (KB)')
plt.ylabel('Number of Files')
bins = int(max(file_size)/bin_interval)
plt.hist(file_size, bins=bins)
plt.savefig(os.path.join(fig_dir, 'parsed_file_stats.jpg'), dpi=dpi)
plt.close()
return anomalies_name紀錄file logger的程式如下
def set_logger(log_path, log_name, mode='a', format='%(message)s'):
"""Set Logger
This function initialize a file logger object.
Parameters
----------
log_path: string
This is the path of log file.
log_name: string
This is the name of logger object.
format: string
This is the log format.
Returns
-------
logger: logging.logger object
This is the logger object that user can use.
"""
# Logging Settings
logger = logging.getLogger(log_name)
logger.setLevel(logging.DEBUG)
# Delete all the handlers in the logger
logger.handlers = []
# Set the mode 'a'(apend) -> 'w'(overwrite)
file_handler = logging.FileHandler(log_path, mode=mode)
file_handler.setLevel(logging.DEBUG)
# Set logging format
formatter = logging.Formatter(format)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
return logger對檔案大小進行分析是為了確定,毀損或異常的檔案占整體的比重。
若比例很小,我們則可以大膽的直接捨棄這些異常文檔,但比例若太大,我們則需設計例外處理,取得其他檔案格式或是載點。
目前所有轉出的檔案,檔案大小分析數據及圖形如下。
解析後的檔案大小若小於1 KB,我們則認定為檔案異常,並且以logging紀錄異常,並記錄最小正常的檔案以供檢驗。
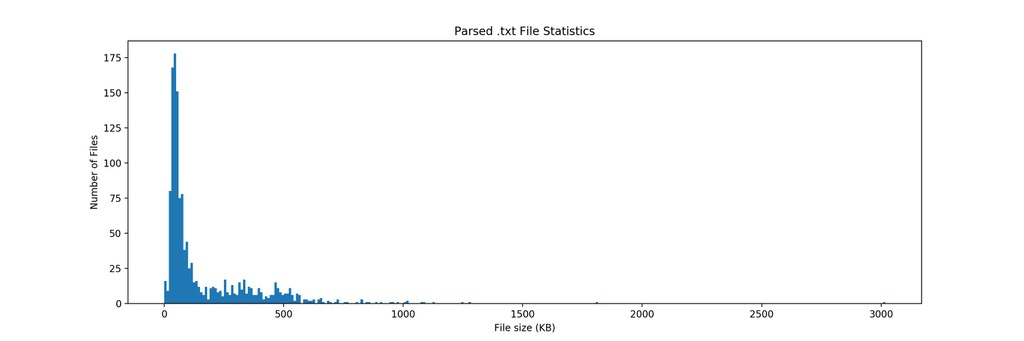
統計數據
- 正常文檔數量:1340
- 異常文檔數量:13
- 異常文檔比例:0.9701 %
遭過濾文檔
- Rip-Foster-in-Ride-the-Gray-Planet.txt (0.00 KB)
- The-Holes-Around-Mars.txt (0.00 KB)
- 1-2986.txt (0.05 KB)
- After-The-Ending.txt (0.05 KB)
- After-the-Cure.txt (0.05 KB)
- Citadel.txt (0.05 KB)
- Forager.txt (0.05 KB)
- Nano-Contestant.txt (0.05 KB)
- Open-Minds.txt (0.05 KB)
- Phantasia.txt (0.05 KB)
- The-Boy-Who-Lit-Up-the-Sky.txt (0.05 KB)
- The-Eden-Plague.txt (0.05 KB)
- Zero.txt (0.05 KB)
觀察解析過後最小的正常文檔Longevity.txt (3.34 KB)後,發現阿就真的這麼短,想要瞬間變30CM都優秀鄉民也是很困難的。
由於異常文檔所佔比例很低,所以決定直接將這13個檔案捨去,得到1327個.txt文檔。
文章大部分解
『始臣之解牛之時,所見無非全牛者﹔三年之后,未嘗見全牛也﹔方今之時,臣以神遇而不以目視,官知止而神欲行。』 - 庖丁解牛
趁周末的時間重新跑了爬蟲程式、文檔轉換解析,接著就是要將每分文檔分為metadata跟content兩大部分。
首先還是老樣子,使用人眼分析器大致可觀察到文檔格式分為兩類,一類是頭尾派、另一類是結尾派(:D)。
頭尾派 的metadata都置於文章的頭尾,而 結尾派 的metadata僅存在文章結尾部分,要如何正確得判斷這兩派並正確分割metadata跟content是這部分程式主要處理的問題。
敝人認為其實metadata其實包含一些有特殊意義的字串,其中 Project Gutenberg 是最有系統的,他是屬於頭尾派的典型,我們觀察文檔A-Bottle-of-Old-Wine.txt。
b'\n\n
A Bottle of Old Wine, by Richard O. Lewis
The Project Gutenberg EBook of A Bottle of Old Wine, by Richard O. Lewis This eBook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included with this eBook or online at www.gutenberg.org
Title: A Bottle of Old Wine
Author: Richard O. Lewis
Illustrator: Kelly Freas
Release Date: September 16, 2009 [EBook #30004]
Language: English
Character set encoding: ASCII
*** START OF THIS PROJECT GUTENBERG EBOOK A BOTTLE OF OLD WINE ***
(content...)
*** END OF THIS PROJECT GUTENBERG EBOOK A BOTTLE OF OLD WINE ***
***** This file should be named 30004.txt or 30004.zip ***** This and all associated files of various formats will be found in: http://www.gutenberg.org/3/0/0/0/30004/
...但是仍有其他的 頭尾派 的格式不如 Project Gutenberg 般明顯,例如我們觀察的文檔Accelerando.txt。
b'\n\n
Accelerando
A novel by Charles Stross
Copyright (c) Charles Stross, 2005
Published by
Ace Books, New York, July 2005, ISBN 0441012841
Orbit Books, London, August 2005, ISBN 1841493902
License
Creative Commons License Copyright (c) Charles Stross, 2005. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 2.5 License. Full terms and conditions at:
http://creativecommons.org/licenses/by-nc-nd/2.5/
Summary:
You are free to copy, distribute, display, and perform the work under the following conditions:
* Attribution. You must attribute the work in the manner specified by the author or licensor. * Noncommercial. You may not use this work for commercial purposes. * No Derivative Works. You may not alter, transform, or build upon this work. * For any reuse or distribution, you must make clear to others the license terms of this work.
If you are in doubt about any proposed reuse, you should contact the author via: http://www.accelerando.org/
Dedication
For Feorag, with love
Acknowledgements
This book took me five years to write - a personal record - and would not exist without the support and encouragement of a host of friends, and several friendly editors. Among the many people who read and commented on the early drafts are: Andrew J. Wilson, Stef Pearson, Gav Inglis, Andrew Ferguson, Jack Deighton, Jane McKie, Hannu Rajaniemi, Martin Page, Stephen Christian, Simon Bisson, Paul Fraser, Dave Clements, Ken MacLeod, Damien Broderick, Damon Sicore, Cory Doctorow, Emmet O\'Brien, Andrew Ducker, Warren Ellis, and Peter Hollo. (If your name isn\'t on this list, blame my memory - my neural prostheses are off-line.)
I mentioned several friendly editors earlier: I relied on the talented midwifery of Gardner Dozois, who edited Asimov\'s Science Fiction Magazine at the time, and Sheila Williams, who quietly and diligently kept the wheels rolling. My agent Caitlin Blasdell had a hand in it too, and I\'d like to thank my editors Ginjer Buchanan at Ace and Tim Holman at Orbit for their helpful comments and advice.
Finally, I\'d like to thank everyone who e-mailed me to ask when the book was coming, or who voted for the stories that were shortlisted for awards. You did a great job of keeping me focused, even during the periods when the whole project was too daunting to contemplate.
Publication History
Portions of this book originally appeared in Asimov\'s SF Magazine as follows: "Lobsters" (June 2001), "Troubadour" (Oct/Nov 2001), "Tourist" (Feb 2002), "Halo" (June 2002), "Router" (Sept 2002), "Nightfall" (April 2003), "Curator" (Dec 2003), "Elector" (Oct/Nov 2004), "Survivor" (Dec 2004).
Contents
Part 1: Slow Takeoff
+ Lobsters + Troubadour + Tourist
Part 2: Point of Inflection
+ Halo + Router + Nightfall
Part 3: Singularity
+ Curator + Elector + Survivor
(content...)
(THE END: June 1999 to April 2004)
***
If you have enjoyed this book, you can make the author a happy man by buying a copy of one of the dead-tree editions.
To find out more about "Accelerando", including where to buy a copy, please visit:
http://www.accelerando.org/
***
A free ebook from http://manybooks.net/這份文章從目錄(contents)開始就可算是本文開始了,但是沒有明確的分界點,若是以contents(目錄)為開始,the end最為文章結尾擷取,要擔心是否有意外的可能性。
我就以目前觀察到的A-Bottle-of-Old-Wine.txt、Accelerando.txt為兩個頭尾派的典型,進行大致上的文章分類。
分類架構
- 若文檔前20行開頭為”The Project Gutenberg”則歸類為 head_tail_1
- 若文檔前20行內還沒進入本文(20行內包含任一特殊字串
author,title,license,acknowledgements, …),則歸類為 head_tail_2 - 其他都被分類到 tail
先觀察數量分布情形,簡單寫一個統計的程式,接著檢查 head_tail_2 、tail 兩類中是否有例外。
def analyze_metadata_type(txt_dir, result_dir):
"""Analyze Metadata Type
This function analyze the proportion of each metadata type.
- head_tail_1: The Project Gutenberg style
- head_tail_2: The metadata is in head in tail of the article
- tail: the rest of them
Parameters
----------
txt_dir: string
This is the directory of the parsed .txt files.
result_dir: string
This is the directory to save the results of analyzed results.
"""
# Initialize statistics
head_tail_1 = 0
head_tail_2 = 0
tail = 0
special_texts = ['author', 'title', 'license', 'acknowledgements']
# Logging Settings
log_path = os.path.join(result_dir, 'metadata_stats.log')
log_name = 'analyze_metadata_type'
logger = set_logger(log_path, log_name, mode='w', format='%(message)s')
# Read parsed .txt files
txt_files = [x[2] for x in os.walk(txt_dir)][0]
for txt_file in txt_files:
with open(os.path.join(txt_dir, txt_file), 'r') as read_file:
lines = read_file.readlines()
meta = ''.join(lines[:20])
tail_flag = True
if 'the project gutenberg' in meta.lower():
head_tail_1 += 1
tail_flag = False
else:
meta = ''.join(lines[:20])
for special_text in special_texts:
if special_text in meta.lower():
head_tail_2 += 1
tail_flag = False
break
if tail_flag:
tail += 1
# Record statistics
logger.info('Type 1 (head-tail-1): %d' %head_tail_1)
logger.info('Type 2 (head-tail-2): %d' %head_tail_2)
logger.info('Type 3 (tail): %d' %tail)
logger.info('-> Total: %d' %(head_tail_1 + head_tail_2 + tail))
# Draw pie chart
# Figure settings
fig_dir = os.path.join(result_dir, 'fig')
if not os.path.exists(fig_dir):
os.makedirs(fig_dir)
plt.figure()
fig1, ax1 = plt.subplots()
ax1.pie([head_tail_1, head_tail_2, tail],
labels=['head_tail_1', 'head_tail_2', 'tail'],
explode = (0.1, 0, 0),
autopct='%1.1f%%',
shadow=True,
startangle=90)
ax1.axis('equal')
plt.savefig(os.path.join(fig_dir,'metadata_type_pie_chart.jpg'), dpi=200)
plt.close()統計數據
- Type 1 (Head-Tail-1): 1114
- Type 2 (Head-Tail-2): 81
- Type 3 (Tail): 132
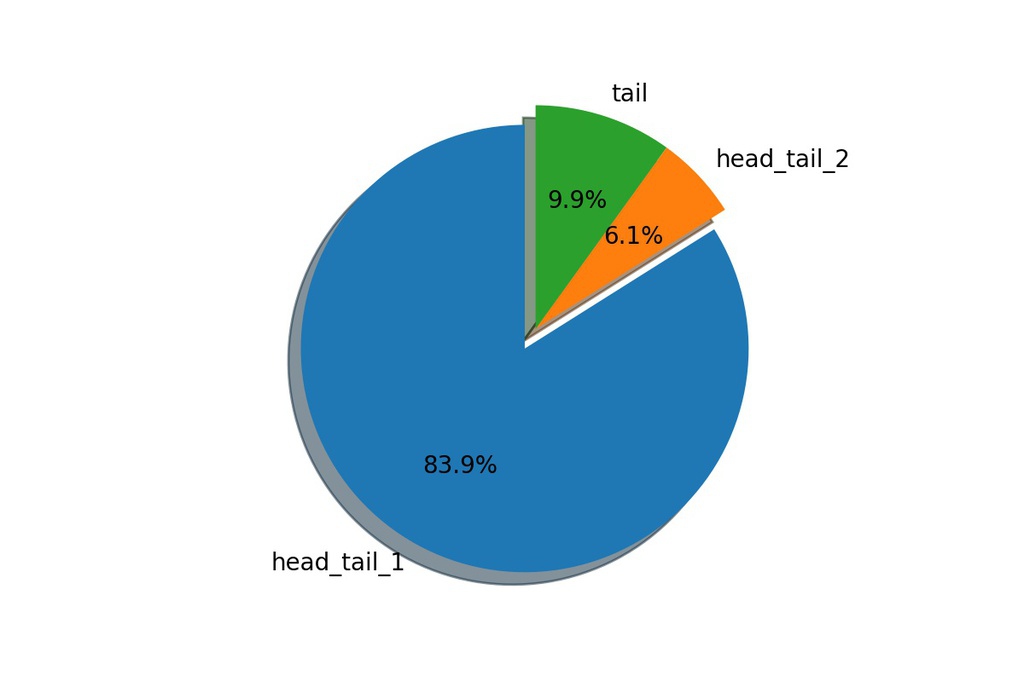
依照Divide-and-Conquer的概念,我們先對 head_tail_1 進行處理,再考慮其他的部分…
經過了一整個下午的觀察,發現根本沒有什麼Type 1、2、3之分,只有分 Project Gutenberg 跟 其他 這兩類。
而且 Project Gutenberg 內部的格式還不統一,總有些例外以及多本書合集的現象,搞得我一個頭兩個大,我只能盡量先以一些人為的Rule來做初步的切割,但是又感覺Rule太過於主觀,應該要多參考其他文獻的處理方法。
由於Rule制定是依照文檔格式case-by-case的,所以就不丟Rule上來說明了,有興趣有閒時間再慢慢修改程式碼。
依照目前大致切出來的文章content其實還是有殘留一些非語句的字串,希望最終目標,是將全部文章依照句子經行重整,之後再去頭去尾過濾後之後應該會是比較完美的結果。
def extract_metadata(txt_dir, txt_file, ext_dir):
"""Extract Metadata
This function categorize the metadata and extract the metadata and content
corespondingly.
Parameters
----------
txt_dir: string
This is the directory of the parsed .txt files.
txt_file: string
This is the file name of the parsed .txt files.
ext_dir: string
This is the directory of the extracted files.
"""
# Read parsed .txt files
txt_ext_dir = os.path.join(ext_dir, \
txt_file.replace('.txt', '').replace('.', ''))
if not os.path.exists(txt_ext_dir):
os.makedirs(txt_ext_dir)
with open(os.path.join(txt_dir, txt_file), 'r') as read_file:
lines = read_file.readlines()
meta = ''.join(lines[:20])
if 'project gutenberg' in meta.lower():
# Process Type 1 Metadata
extract_type_1(lines, txt_ext_dir)
else:
# Process Type 2 Metadata
extract_type_2峰迴路轉
遇到問題時,最佳的解決方法就是直接詢問遇過類似問題的人。
今天跟隔壁處理文字檔案的部門的同仁討論起問題,他說道曾經有看過本文擷取Github的專案,這是一個用Machine Learning Model擷取網頁中本文部分,但是用這個方案可能需要從.epub轉換步驟開始做起。
另一個是自己最簡單的猜想,當下也覺得滿合理的,就是接續之前程式初步擷取出的content,先利用自然語言處理將整篇文章的句子依序排列。
由於我們比較在意去除雜訊,對本文內容減損倒是不太重要,所以我們過濾掉一定比例可能含有”雜質”的部分(利用文字density判斷?)。
由於第一個方法是有論文資料佐證,我們就針對上述的第一點開始進行測試效果,除非我們真的逼到絕望的地步才用第二個猜想。 老樣子先fork下來,由於專案頁面提到專案是以Python2.7撰寫,而且還沒在Python3上面測試過,所以很有可能要對程式碼進行修改。 接著,依照專案頁面上的指示clone、安裝dependenceies、安裝套件,沒想到馬上撞到錯誤,似乎是在windows底下C compiler的問題。
文章細部分解
小記
[2017-10-13] 這個小專案從7月開始玩,但是從一開始衝勁滿滿到現在一直放著…看來我的決心還是不夠!只好11月來一決勝負、衝一波!!!
留言